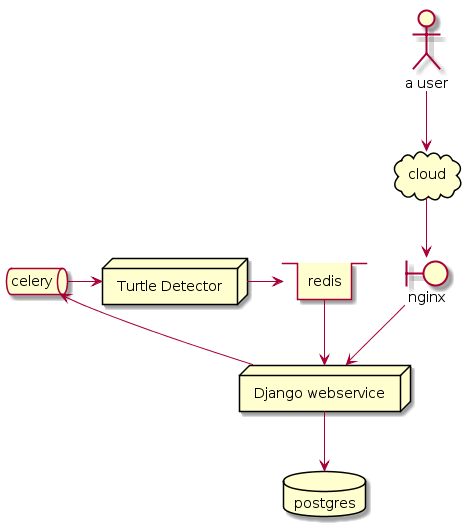
I have worked with a bunch of companies that launched major initiatives to move their hardware onto the public cloud. None of those companies managed to get their CPU utilization over 10%. At my current job we run Java with 10-20% cpu utilization and 90% memory reserved for the JVM. The standard software development approach does not result in amazing hardware utilization rates.
The consulting clients we worked with at my previous job expressed a lot of interest in increasing efficiency. We theorized complex tagging and did proof of concepts with Cloudability. But I do not recall actual savings coming out of it. Although there was a lot of complaining about the AWS bill being high.
One Fortune 500 company I worked with had a dev environment with a huge number of hosts (1000+) that were basically never utilized at all. That company only used continuous delivery in development, not for production deployments. The other obvious issue at that company was their reluctance to rely on AWS Autoscaling groups to handle load spikes. They allocated for peak load despite running in the cloud.
One concern that came up a couple times was that Autoscaling groups have a scaling response rate in the order of minutes. In the event of a traffic spike, it might be 5-10 minutes before extra hosts come online.
If you are worried about unexpected instantaneous peaks write a fallback. Serve a landing page our of cache and sit tight. There is no magic solution to instantly increasing your traffic by 100x without scaling preemptively.
The largest websites in the world scale ahead of time. We know when we will get lots of traffic historically. You know when your Super Bowl add is going live. Scale up a week before hand. Run load tests to make sure you can handle the traffic.
Run your servers at 30-60% utilization. Build a fallback page for big instantaneous peaks. Most importantly know ahead of time what your traffic is going to look like so you can prepare.