I released a short demo of AI assisted vibe coding to the youtube channel. Basic games like this are one of my favorite use cases for vibecoding. LLMs are pretty good at it and the pay off is quick. Back in my teens I tried to learn programming to make games. I’d have gotten a lot farther if we’d had AI then instead of trying to figure out C++ from a two inch think book!
In 2023 I was one of the many software engineers whose management pushed them into trying Github Copilot. I was not impressed. At the time Copilot was basically pointless for Java developers. IntelliJ already had Intellisense which did everything Copilot did, but more deterministically.
In retrospect autocomplete was not the use case for AI to assist in the programing process. Personally, I find the AI chatbots to be very useful coding assistants for writing scripts and functions. And this last year AI coding Agents have really come into their own.
I’ve never been a python guy despite using it for light scripting tasks for a decade. But lately I’ve been using it a lot more because Claude can consistently create working 500~ line python scripts in a couple prompts. The days when AI spit out code that didn’t even run are mostly in the past now.
AI is just much better at coding now than it was in 2023. And I suspect the ‘autocomplete’ use case is just a bad one for AI. The more powerful models tend to produce output more slowly. You are looking at a 15+ second wait with edge models. In Claude Code and other agents, multiple 15+ second waits is pretty annoying. It’s like compiling huge java projects. For me I find the chatbot model works great. You write up a prompt, provide examples and context then Claude spits out a running program. You test it and iterate. Autocomplete has the problem that edge models are never going to have the latency that you want when you push ctrl-shift-enter. It just feels better to use an agent or chatbot.
I’m working on a new book on Vibe Coding for people who don’t know how to code. Using LLMs to build simple programs unlocks a lot of programming ability for people who either tried and failed to learn to program or never got started. You no longer need to learn the basics of programming logic or syntax to build useful programs to solve your problems.
The current target of the book is people who don’t know how to code but are willing to learn to run and test computer programs they create through Vibe Coding.
As part of this process I’m doing some research comparing free and paid LLM models for programming use.
For each model I pasted the same prompt in and took the first result. I saved the code into a folder which already had pygame installed via pip and ran it directly.
“Please create a game for me using python and pygame. In the game the player should navigate a 2d space using the arrow keys. In this game there should be a maze like region with rocks and stalagmites. Inside the region should be chests which contain gold. The player should be able to navigate the maze and collect gold from the chests.”
LLMs are at the point where they can reduce toil for software engineers across a host of use cases. Here we will explore a few I’ve thought of.
Reduces time spent on toil
Resize this button -> AI
Refactor this function -> AI
Connect these endpoints -> AI
Write more tests -> AI
Add more comments -> AI
Create PlantUML diagrams from a sketch -> AI
First pass code reviews -> AI
Reduces time spent researching small things
AI is a better stack overflow
Examine stack traces
Easier to write architecture documents
Faster development of small utilities
What AI still cannot do
Test if a library will work for your use case
Respond to outages
Decide the product direction
Argue with stakeholders
Yell at people who want to do stupid things
A few opportunities to reduce operational toil
AI can review graphs and notice changes
AI can check if a website is down
File bug reports
For me the most valuable use of Claude as a coding assistant has been how it makes getting started much easier. Usually, to program a swift game I’d have to spend a couple hours breaking into swift development and building up my program off of examples. Claude was able to create a basic version of the game I wanted off of a detailed prompt. It didn’t manage to create the game in one shot, I had to edit the code a bit to get it to run. But it turned a project that would have taken me a few days into one that took a few hours.
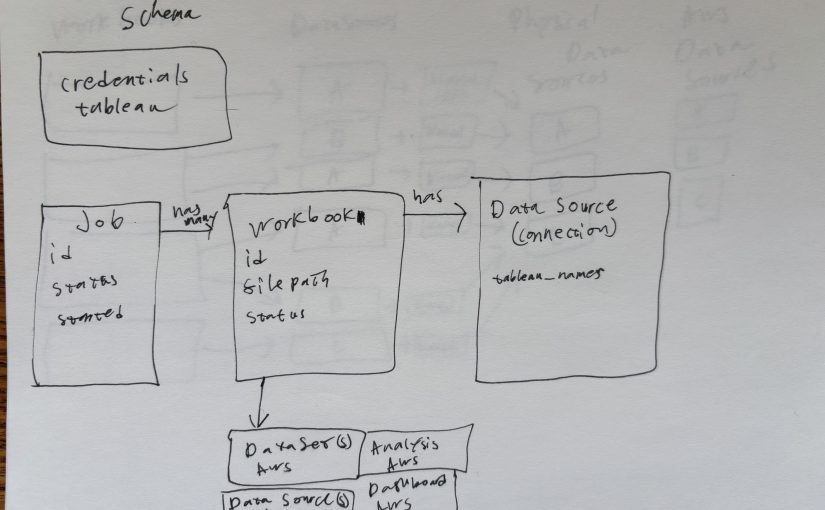
If you’ve ever worked with PlantUML or Mermaid before it’s easy to forget the domain specific language used to build the diagrams. You sketch out your whiteboard diagram, discuss it with coworkers and are ready to start on your architecture document only to sit there stumped trying to remember how to convert your drawing into PlantUML.
Well the good news is that Claude can do it for you. Just take a picture of your whiteboard and Claude can convert it into Mermaid or PlantUML for you. I tried both and Claude is better at Mermaid but can do PlantUML.
Unfortunately, Claude’s first attempt had an error. I fiddled with it a bit in the editor, but Claude was able to fix it faster than I was.
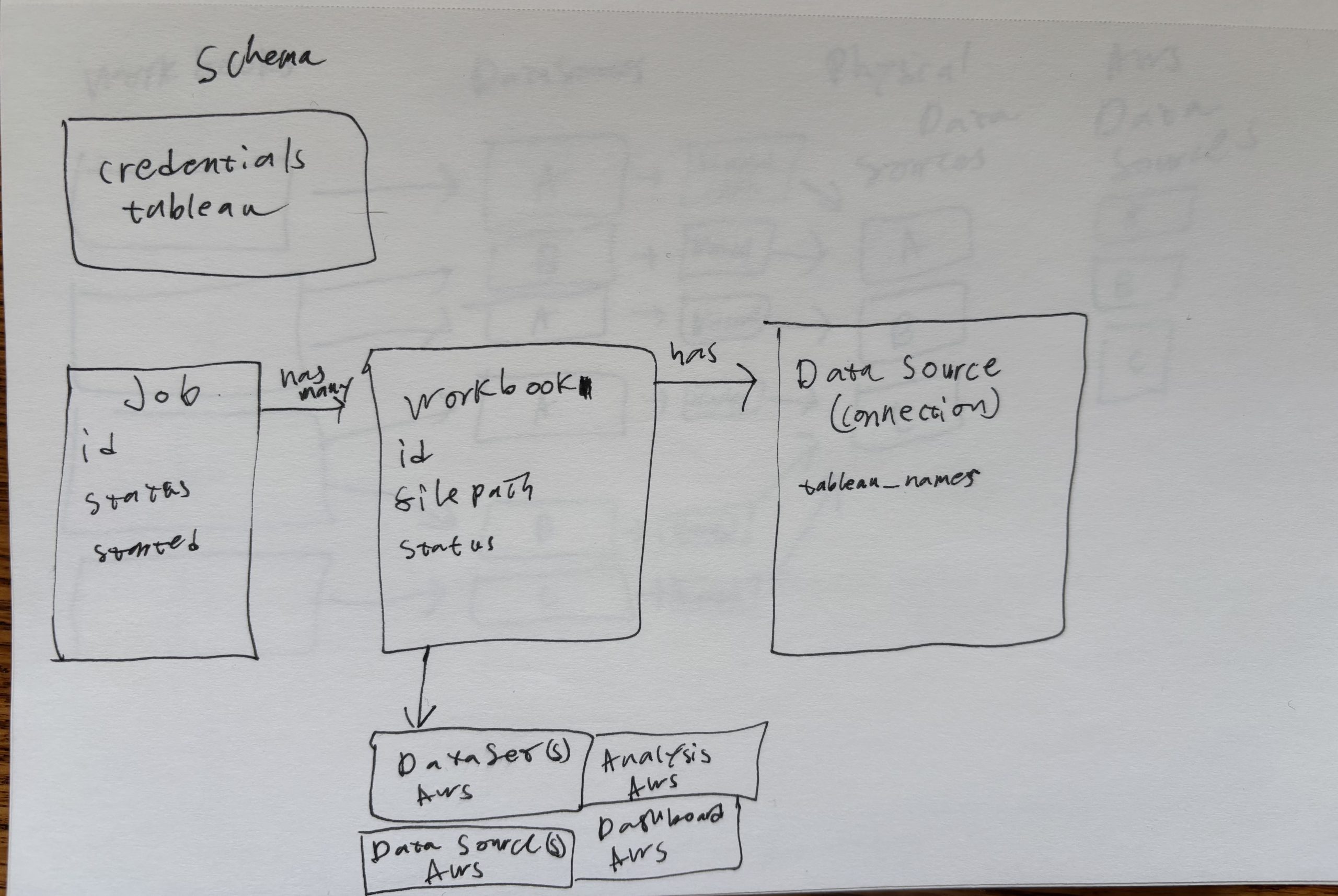
Claude fixed the issue and I was able to generate the following PlantUML visualization.
Here is the original image compared against the PlantUML Claude generated. The relationships are correctly mapped even if the physical placement is a bit different.
Lastly, I asked Claude to do the same thing with the Mermaid diagram visualizer. Mermaid does the same things as PlantUML, it’s just newer and easier to use.
To my surprise Claude not only managed to do it in one attempt. But Mermaid is built into the Anthropic UI.
If you’re ever stuck trying to remember the PlantUML DSL just ask Claude to do it.