This post has moved to my new website estimating.dev. Which is the place for all information and best practices around software development project estimates.
Here is the link to this posts new home.
This post has moved to my new website estimating.dev. Which is the place for all information and best practices around software development project estimates.
Here is the link to this posts new home.
I have gotten back into reading Software Engineering books. It has been a good change of pace to study a bit in the mornings. My current focus is on Estimation. I want to come up with a better more accurate way for us to estimate software projects in agile environments.

These two books are great references. Designing Data-Intensive Applications is a good read and believe it or not my workplace still uses Java 8 so Java Performance is not out of date.

I got these two management books back when I was a manager for a few months. But I haven’t dug into them yet.

Agile Software Development was a textbook back in University. It is a funny book since it has about as much space devoted to Agile as it does to Object Oriented programming. The Mythical Man-Month is fun because of all the references to technology in the old days before the modern web.

Building Products for the Enterprise is a product book, but I really like how it really explains what those Product Owners are up to all day.

Following on my earlier post “How much is turnover costing your company?” this post is about how much using non-standard technology stacks costs your company. Lets say company A is high performance company with a custom functional programming stack that uses Haskell and Miso for development. Company A doesn’t ship a lot of bugs to production, in fact they run CI/CD with deployments to prod everyday. Their SAAS product is one of the best in the industry and is growing at a good rate.
Now Company A has a competitor in the form of Company B. In this case B does stand for Boring. Company B offers a SAAS product that is almost identical to the one Company A sells but Company B’s has more bugs because they use Java. In fact Company B uses Java with Spring Boot and ReactJS. Both Company A and Company B started in 2018 when React was already mainstream. Company B also uses CI/CD deployments but they can only deploy to production once a week because there are so many bugs. Company B also hired a QA Engineer to help support the pipeline because of an embarrassing outage that CompanyA used in a humiliating Ad.
In January 2019 both companies raise a round of founding for 10 million dollars. The mandate from the VCs is to 10x the company in size and destroy the competition. Both companies need to start hiring fast. Throughout 2019 CompanyA has an advantage, there are a bunch of passionate Haskell engineers that want to work on their product. Both Company A and B reach their growth targets and hit 100 engineers that year.
Fortunately, things go well for both companies in 2020. The market is growing and revenues are increasing. The VCs call for more growth. Now we want to grow engineering to 500 engineers.
Now Company A has a problem. They already hired all the passionate Haskell+Miso engineers they could find. Any new engineers will take 12 months to train on their technology stack. CompanyB doesn’t have this problem everyone still remembers how ReactJS and Spring Boot work even though they are no longer the top technologies. Company B only needs 6 months to train a new engineer on their technology stack.
Lets run the numbers. How much is it going to cost to onboard 400 new engineers for each company?
We will keep our 2 year average tenure estimate and use 12 months of onboarding for company A. Each engineer has a total cost of 200k including salary, equity, benefits, taxes and insurance.
Each engineer is going to cost around 100k to onboard at Company A.
Each engineer is going to cost about 50k to onboard at Company B.
Now the next question, how long will it take each company to get all 400 new engineers fully operational?
My assumption is that it takes 1 fully onboarded engineer to train a new engineer. Each company has 100 engineers to start so at the beginning the first 100 engineers will train the next 100. Then each company will have 200 engineers to train the next 200. Then things calm down a little and we have 400 engineers to train the last 100.
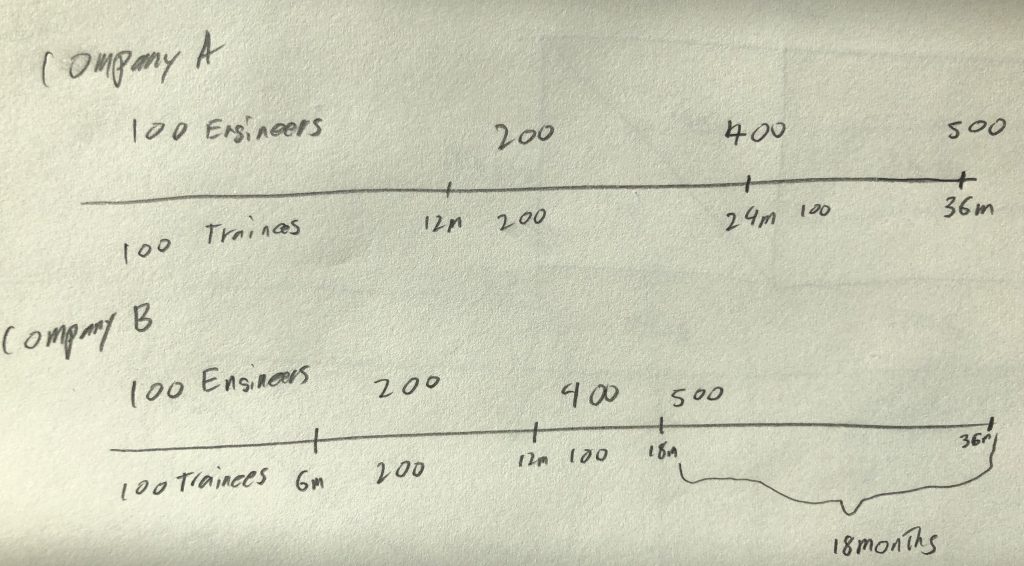
After 12 months Company B has double the trained engineers Company A has. At 18 months Company B is finished onboarding and can have all 500 engineers focus on the product. Company A won’t catch up for another 18 months.
Most people will agree that Company A’s functional programming stack is not going to make up for the extra engineer years that Company B has at this point.
This post has moved to my new website estimating.dev. Which is the place for all information and best practices around software development project estimates.
Here is the link to this posts new home.
Have you ever had a great email thread about a feature? You and your manager hashed out a solution with the product team and everyone is in agreement. All that is left to do, is to create a JIRA ticket and get working. Now wouldn’t it be nice if you could just LINK THE EMAIL THREAD IN THE STORY!
I have seen email archives, I know they exist. Linux has them. My employer even has email archives. But how can I link to the archive from Outlook? There should be a way to do this super simple thing to share my emails in a story.
I am going to investigate how the email archives work at my employer.