When you are working on a feature it makes sense to make incremental commits as you proceed with the work. Then when you are done you want to just open a Pull Request and wait for approvals. But it is important to squash your commits into a single commit before merging into the master branch. The reason is if you need to revert your code change, you can revert a single commit and move on. You don’t want to be in a position where you have a serious bug in production, and you are trying to figure out if you reverted all of the commits. Save yourself the panic and trouble by squashing before you commit to your master branch. Some services like github will automatically squash for you, use that feature if you have it.
Useful git commands for squashing
# git --amend amends your last git commit git commit --amend # rebase is the command used to actually squash commits # git rebase -i HEAD~4 rebases the last 4 commits including the head commit
# the -i toggles interactive mode which opens an editor
git rebase -i HEAD~4
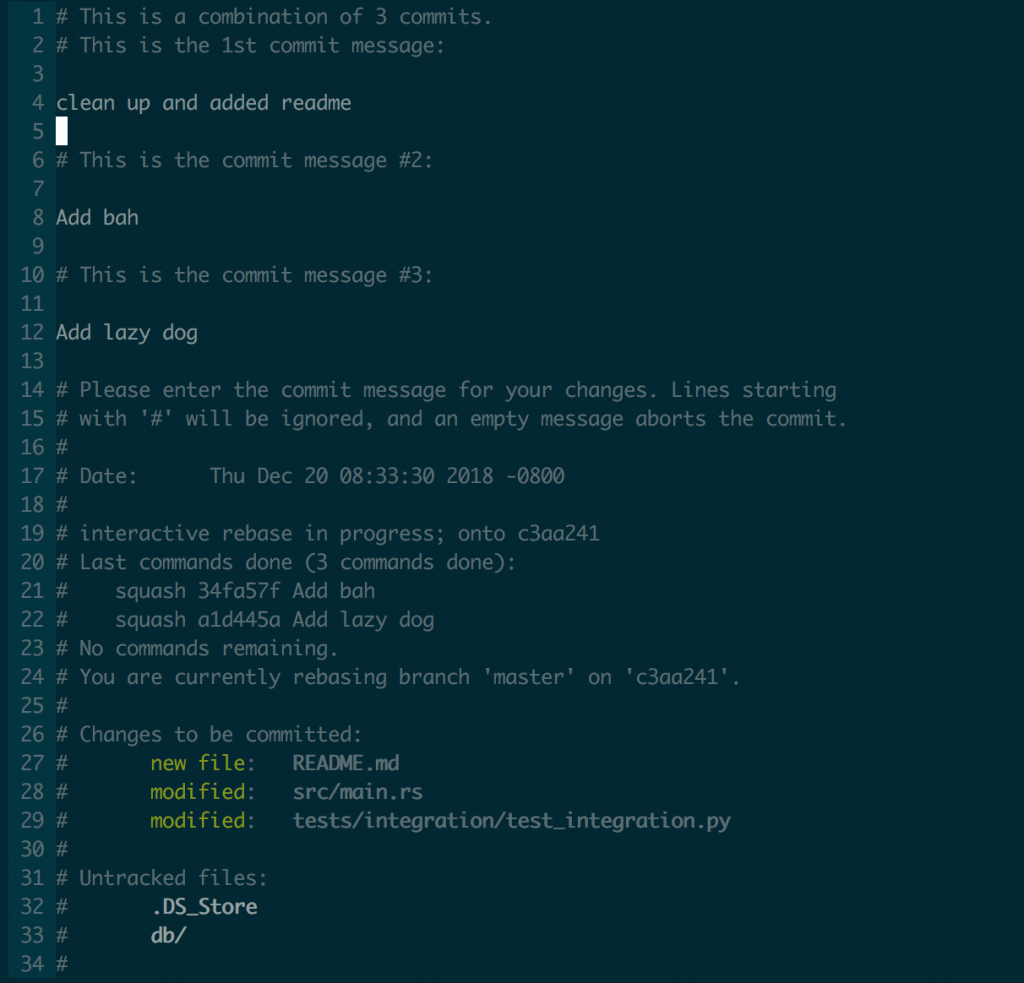
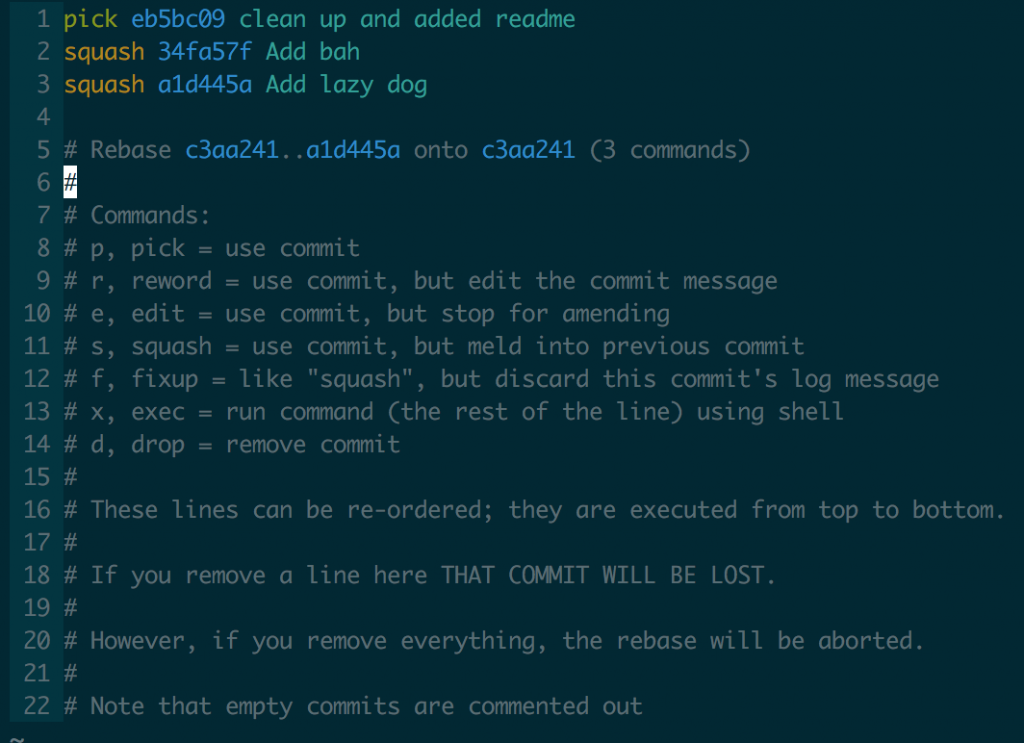
When you run the command git will open a text editor that asks you to choose what to do with each commit.

The default is the vi or vim editor. In this window you want to change the command for the commits you want to squash.
Then the next window will give you a chance to modify the commit message for your new combined commits.