AWS Athena is a managed big data query system based on S3 and Presto. It supports a bunch of big data formats like JSON, CSV, Parquet, ION, etc. Schemas are applied at query time via AWS Glue.
To get started with Athena you define your Glue table in the Athena UI and start writing SQL queries. For my project I’ve been working on heavily nested JSON. The schema for this data is very involved so I opted to just use JSON path and skip defining my schema in AWS Glue. Of course that was after I wasted two days trying to figure out how to do it.
Setting up AWS Athena JSON tables
AWS Athena requires that your JSON objects be single line. That means you can’t have pretty printed JSON in your S3 bucket.
{
"key" : "value",
"hats" : ["sombrero", "bowler", "panama"]
} If your JSON files look like the example above they won’t work. You have to remove line breaks so your json objects take up a single line.
{"key":"value","hats":["sombrero","bowler","panama"]}One tripping point is that its not obvious in the docs how to define your table if you aren’t going to use Glue schemas.
My dataset consists of S3 objects that look like this.
{
"data":
{
"component1":
{
"date": "2020-02-24",
"qualifier": "Turnips",
"objects":
[
{
"type": " bike",
"date": "2022-01-14",
"xy" : {
"xy-01": 1432
}
},
{
"type": "pen",
"date": "2021-07-11",
"xy" : {
"xy-01": 11
}
},
{
"type": "pencil",
"date": "2021-07-11",
"xy" : {
"xy-01": 67
}
}
]
},
"component2":
{
"date": "2021 - 03 - 15",
"qualifier": "Arnold",
"objects":
[
{
"type": "mineral",
"date": "2010-01-30",
"xy" : {
"xy-01": 182
}
}
]
},
"component3":
{
"date": "2020-02-24",
"qualifier": "Camera",
"objects":
[
{
"type": "machine",
"date": "2022-09-14",
"xy" : {
"xy-01": 13
}
},
{
"type": "animal",
"date": "2021-07-11",
"xy" : {
"xy-01": 87
}
}
]
}
}
}To use Athena and JSON Path for a nested JSON object like this. You simply define a single column called “data” with a string type and you are done.
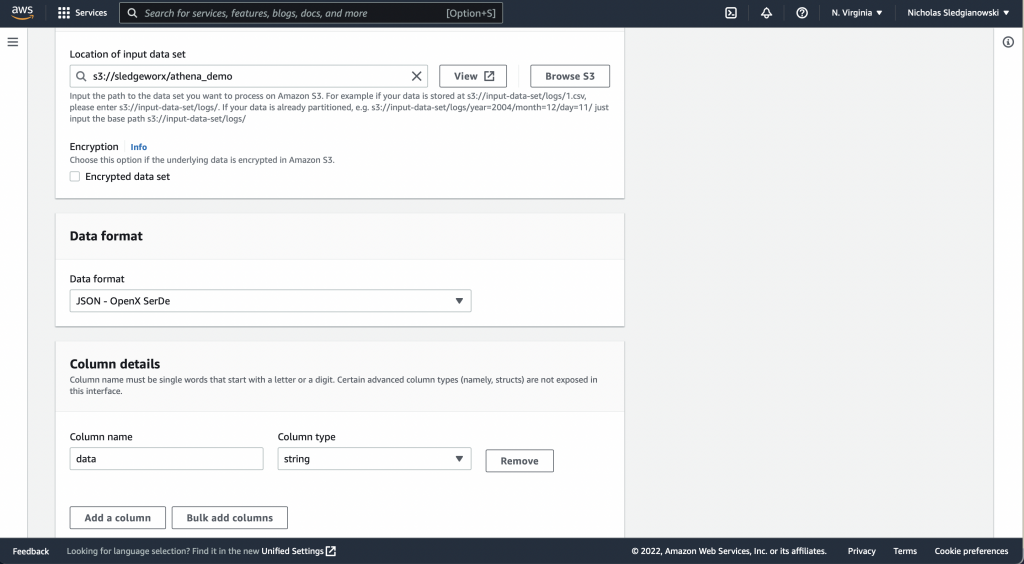
Then you query using JSON Path like this.
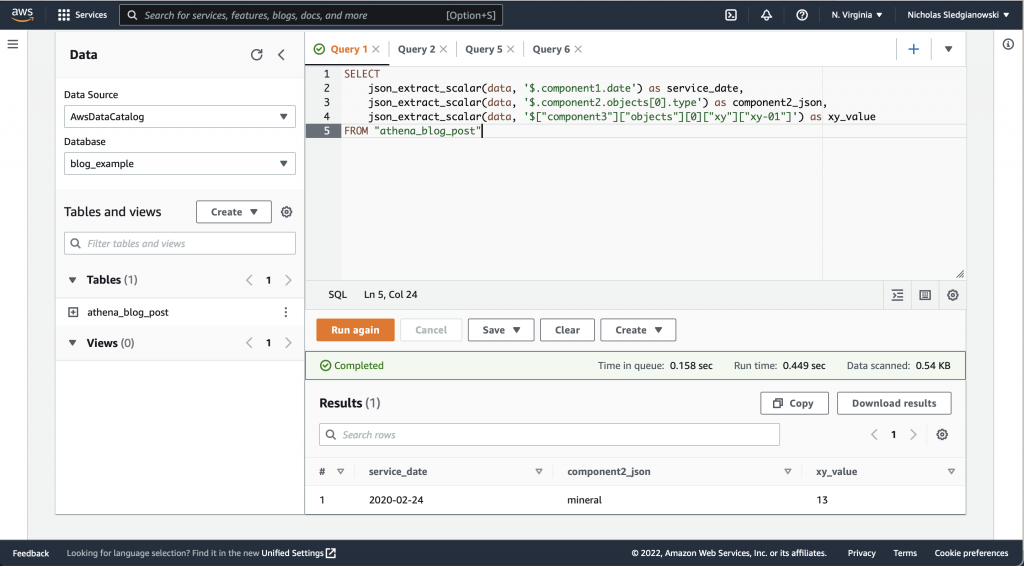
Example of a simple JSON PATH Athena query
SELECT
json_extract_scalar(data, '$.component1.date') as service_date,
json_extract_scalar(data, '$.component2.objects[0].type') as component2_json,
json_extract_scalar(data, '$["component3"]["objects"][0]["xy"]["xy-01"]') as xy_value
FROM "athena_blog_post"Note that the json_extract and json_extract_scalar functions take a string column as their argument.
One thing to watch out for is that the dash character “-” is banned from the first type of JSON Path. So you might have to use the bracket notation instead.
Using the UNNEST operator to pivot and flatten JSON arrays of objects.
Often when working with JSON data you will have arrays of objects. You might want to split each entry in a nested array into its own row. This can be accomplished with the UNNEST operator.
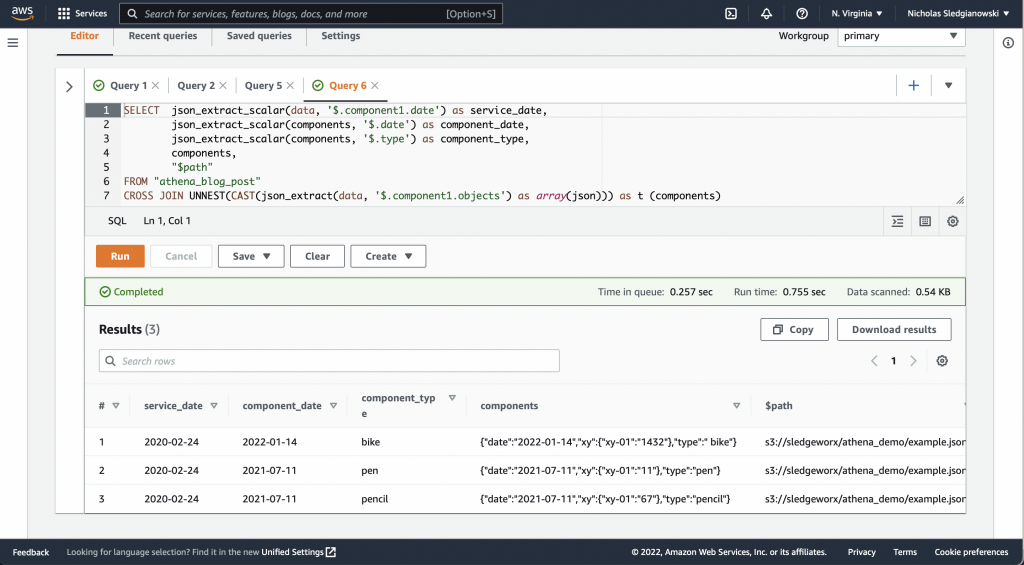
Here we have used json_extract to retrieve a nested JSON object. Then we cast it into a json array which the UNNEST operator accepts.
SELECT json_extract_scalar(data, '$.component1.date') as service_date,
json_extract_scalar(components, '$.date') as component_date,
json_extract_scalar(components, '$.type') as component_type,
components,
"$path"
FROM "athena_blog_post"
CROSS JOIN UNNEST(CAST(json_extract(data, '$.component1.objects') as array(json))) as t (components)